🎯 Definindo o Escopo
Antes de escrever uma linha de código, você precisa definir exatamente o que seu agente faz. Agente de código? Assistente de pesquisa? Automação de deploy? Cada tipo exige ferramentas diferentes, níveis de autonomia distintos e modelos com capacidades específicas. Sem escopo claro, você constrói um Frankenstein que faz tudo mal.
Checklist de Escopo do Agente
Tipo: agente de código (lê/escreve arquivos), assistente (responde perguntas com contexto) ou automação (executa pipelines)?
Ferramentas: quais ações concretas o agente precisa executar? Liste de 3 a 5 para começar
Autonomia: o agente pode agir sozinho ou precisa de confirmação humana para cada ação?
Modelo: qual LLM será usado? Local (Ollama) ou API? Qual tamanho (8B, 70B)?
💡 Comece Pequeno
Não tente construir o Claude Code de primeira. Comece com um agente que faz UMA coisa bem: ler arquivos e responder perguntas sobre o código. Depois adicione escrita, depois execução. O Claude Code levou meses para chegar em 40+ ferramentas — seu MVP precisa de 3.
⚡ Stack Tecnológica
Nosso agente será construído com Python 3.11+ e Ollama como provedor de LLM local. O Ollama roda modelos open-source diretamente na sua máquina — sem custos de API, sem latência de rede, sem dependências externas. A biblioteca ollama para Python oferece uma interface limpa e compatível com o padrão OpenAI.
Setup Inicial — Python + Ollama
# Terminal: instalar dependências
pip install ollama
# Python: testar conexão
from ollama import chat
response = chat(
model='qwen3:8b',
messages=[
{'role': 'user', 'content': 'Hello, are you working?'}
]
)
print(response.message.content)
# Pré-requisito: Ollama rodando em localhost:11434
# Instale: https://ollama.ai → ollama pull qwen3:8bPython 3.11+: tipagem moderna, asyncio maduro, f-strings avançadas
Ollama: servidor local de LLMs — roda Qwen, Llama, Mistral e outros modelos open-source
qwen3:8b: modelo recomendado para agentes — bom suporte a tool calling, roda em 8GB VRAM
📊 Por Que Python + Ollama?
Sem custo de API: modelos rodam localmente, sem tokens cobrados — ideal para desenvolvimento e testes
Privacidade total: código e dados nunca saem da sua máquina — importante para projetos proprietários
Latência baixa: sem round-trip de rede — respostas em milissegundos para modelos pequenos
Ecossistema Python: subprocess, pathlib, asyncio, json — tudo que um agente precisa já vem built-in
🧩 Componentes Essenciais
Todo agente precisa de 5 componentes fundamentais: o loop principal (AgentLoop), o executor de ferramentas (ToolExecutor), o gerenciador de contexto (ContextManager), o armazenamento de memória (MemoryStore) e o controlador de permissões (PermissionController). Cada um mapeia diretamente em um subsistema do Claude Code.
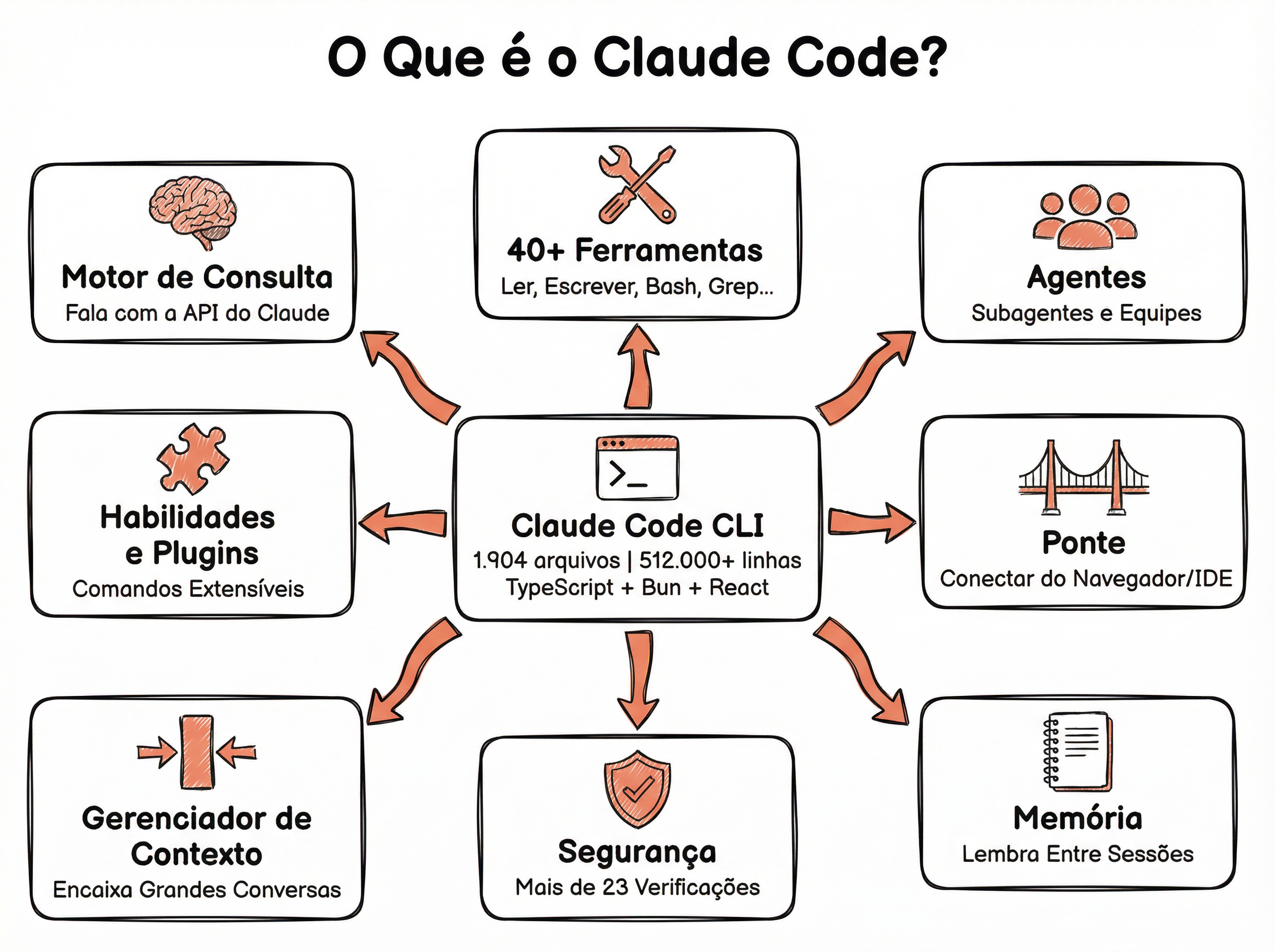
Mapeamento: Claude Code → Python
| Componente | Claude Code | Python |
|---|---|---|
| AgentLoop | queryHaiku / queryLoop | while True + ollama.chat() |
| ToolExecutor | 40+ tools com schemas | TOOL_MAP + dispatch |
| ContextManager | System prompt + CLAUDE.md | trim_messages() |
| MemoryStore | 4 tipos + AutoDream | JSON file persistence |
| PermissionController | 5 camadas allow/deny/ask | JSON config + check() |
💡 Arquitetura Modular
Cada componente deve ser uma classe independente com interface clara. Isso permite trocar o LLM (de Ollama para OpenAI API) sem mexer nas ferramentas, ou adicionar novas ferramentas sem alterar o loop. O Claude Code segue exatamente esse padrão — é o que permite a ele suportar múltiplos modelos e dezenas de ferramentas.
📦 Padrão: Tool Registry
O Tool Registry é o padrão que conecta o LLM às ferramentas. Consiste em duas estruturas: TOOL_MAP (dicionário nome → função Python) e TOOL_SCHEMAS (lista de schemas JSON que o LLM entende). Quando o LLM decide usar uma ferramenta, o registry localiza a função correta e a executa.
Implementação do Tool Registry
# tool_registry.py
from pathlib import Path
import subprocess
# 1. Funções das ferramentas
def read_file(path: str) -> str:
return Path(path).read_text(encoding='utf-8')
def run_shell(command: str) -> str:
result = subprocess.run(command, shell=True, capture_output=True, text=True, timeout=60)
return result.stdout + result.stderr
# 2. Mapa nome → função
TOOL_MAP = {
'read_file': read_file,
'run_shell': run_shell,
}
# 3. Schemas para o LLM
TOOL_SCHEMAS = [
{
'type': 'function',
'function': {
'name': 'read_file',
'description': 'Read contents of a file',
'parameters': {
'type': 'object',
'properties': {
'path': {'type': 'string', 'description': 'File path to read'}
},
'required': ['path']
}
}
},
{
'type': 'function',
'function': {
'name': 'run_shell',
'description': 'Run a shell command',
'parameters': {
'type': 'object',
'properties': {
'command': {'type': 'string', 'description': 'Shell command to execute'}
},
'required': ['command']
}
}
}
]
# 4. Dispatch: executar ferramenta por nome
def execute_tool(name: str, args: dict) -> str:
if name not in TOOL_MAP:
return f"Error: unknown tool '{name}'"
try:
return TOOL_MAP[name](**args)
except Exception as e:
return f"Error: {e}"💡 Descrições São Tudo
O LLM decide qual ferramenta usar baseado na description do schema. Uma descrição vaga = ferramenta mal utilizada. Seja específico: "Read the full contents of a file given its path" é melhor que "Read file". O Claude Code investe dezenas de linhas descrevendo cada ferramenta.
📦 Padrão: Context Manager
A context window é o recurso mais precioso do agente. Cada mensagem, cada resultado de ferramenta consome tokens. Sem gerenciamento, o agente atinge o limite e para de funcionar. O Context Manager monitora o uso de tokens e comprime mensagens antigas quando necessário — exatamente como o AutoDream do Claude Code.
Implementação do Context Manager
# context_manager.py
import json
def estimate_tokens(text: str) -> int:
"""Estimativa simples: ~4 chars por token."""
return len(text) // 4
def trim_messages(messages: list, max_tokens: int = 30000) -> list:
"""Mantém system prompt + mensagens mais recentes dentro do budget."""
# Sempre preservar system messages
system = [m for m in messages if m['role'] == 'system']
non_system = [m for m in messages if m['role'] != 'system']
# Calcular tokens do system prompt
system_tokens = sum(estimate_tokens(json.dumps(m)) for m in system)
budget = max_tokens - system_tokens
# Adicionar mensagens de trás pra frente (mais recentes primeiro)
kept = []
used = 0
for msg in reversed(non_system):
msg_tokens = estimate_tokens(json.dumps(msg))
if used + msg_tokens > budget:
break
kept.insert(0, msg)
used += msg_tokens
return system + kept
class ContextManager:
def __init__(self, max_tokens: int = 30000):
self.max_tokens = max_tokens
self.messages: list = []
def add(self, message: dict):
self.messages.append(message)
self.messages = trim_messages(self.messages, self.max_tokens)
def get_messages(self) -> list:
return self.messages.copy()
def token_usage(self) -> int:
return sum(estimate_tokens(json.dumps(m)) for m in self.messages)📊 Estratégias de Compressão
Truncar antigas: mais simples — remove mensagens do início (o que fizemos acima)
Resumir com LLM: pedir ao modelo para resumir mensagens antigas antes de descartar (AutoDream)
Truncar tool results: saídas de ferramentas longas podem ser cortadas para os primeiros N caracteres
Sliding window: manter sempre as últimas N mensagens — previsível e simples
📦 Padrão: Permission Controller
Um agente sem controle de permissões é uma bomba-relógio. O Permission Controller decide, para cada ferramenta, se ela pode rodar livremente (allow), precisa de confirmação (ask) ou está bloqueada (deny). Usa um arquivo JSON de configuração para que regras possam ser ajustadas sem alterar código.
Implementação do Permission Controller
# permissions.json
{
"read_file": "allow",
"write_file": "ask",
"run_shell": "ask",
"search_in_files": "allow",
"delete_file": "deny"
}
# permission_controller.py
import json
from pathlib import Path
class PermissionController:
def __init__(self, config_path: str = 'permissions.json'):
self.rules = json.loads(Path(config_path).read_text())
def check(self, tool_name: str) -> str:
"""Retorna 'allow', 'ask' ou 'deny'."""
return self.rules.get(tool_name, 'ask')
def request_permission(self, tool_name: str, args: dict) -> bool:
"""Pede confirmação ao usuário para ferramentas 'ask'."""
permission = self.check(tool_name)
if permission == 'allow':
return True
if permission == 'deny':
print(f"BLOCKED: {tool_name} is denied by policy")
return False
# permission == 'ask'
print(f"\n⚠️ Tool: {tool_name}")
print(f" Args: {json.dumps(args, indent=2)}")
resp = input(" Allow? [y/N]: ").strip().lower()
return resp == 'y'Fazer
- ✓ Usar "deny" por padrão para ferramentas desconhecidas
- ✓ Logar cada execução de ferramenta com timestamp e args
- ✓ Separar permissões por ambiente (dev vs prod)
- ✓ Validar argumentos antes de executar a ferramenta
Evitar
- ✗ Dar "allow" para run_shell sem validação de comandos
- ✗ Hardcodar permissões no código — use JSON configurável
- ✗ Ignorar o retorno do permission check antes de executar
- ✗ Confiar no LLM para se auto-limitar — ele não vai
📋 Resumo do Módulo
Próximo Módulo:
5.2 - 🔧 Construindo o Sistema de Ferramentas