💬 Memória de Sessão
A forma mais básica de memória é a lista de mensagens da sessão atual. Cada interação — pedido do usuário, resposta do LLM, resultado de ferramenta — é adicionada à lista. Essa lista é o contexto que o modelo recebe a cada chamada. Sem ela, o agente não saberia o que aconteceu 2 segundos atrás.
Lista de Mensagens — A Base da Memória
messages = [
{'role': 'system', 'content': 'You are a coding agent...'},
{'role': 'user', 'content': 'Fix the bug in main.py'},
]
# After each LLM response:
messages.append({'role': 'assistant', 'content': response})
# After each tool result:
messages.append({'role': 'tool', 'content': result, 'name': tool_name})System message: define o comportamento do agente — é a primeira mensagem e raramente muda
User/Assistant: o diálogo vai crescendo a cada iteração do loop
Tool results: saída das ferramentas é adicionada como mensagens do tipo tool
💡 Atenção ao Crescimento
A lista de mensagens cresce indefinidamente. Uma sessão longa pode facilmente ultrapassar o limite de contexto do modelo. Nos tópicos 4 e 5 deste módulo, veremos como lidar com isso usando sliding window e resumo com LLM. Por enquanto, implemente o append básico e monitore o tamanho.
💾 Persistência
Memória de sessão morre quando o processo fecha. Para que o agente "lembre" de sessões anteriores, precisamos salvar em disco. A abordagem mais simples: um arquivo JSON por sessão. Sem banco de dados, sem complexidade — apenas arquivos que você pode inspecionar manualmente.
Persistência com JSON — Uma Sessão por Arquivo
class AgentMemory:
def __init__(self, session_dir='~/.agent/sessions'):
self.dir = Path(session_dir).expanduser()
self.dir.mkdir(parents=True, exist_ok=True)
self.session_id = datetime.now().strftime('%Y%m%d_%H%M%S')
self.messages = []
def save(self):
(self.dir / f'{self.session_id}.json').write_text(
json.dumps({'messages': self.messages}, indent=2))
def load(self, session_id):
data = json.loads((self.dir / f'{session_id}.json').read_text())
self.messages = data['messages']Um arquivo por sessão: nomeia pelo timestamp, fácil de listar e debugar
JSON legível: você pode abrir com qualquer editor e ver exatamente o que aconteceu
Save incremental: chame save() após cada interação para não perder dados em crash
📊 JSON vs SQLite — Trade-offs
JSON: zero dependências, legível, fácil de debugar. Ruim para busca e sessões muito grandes (>50MB)
SQLite: busca rápida, ACID, compacto. Mais complexo, não legível direto, precisa de schema
Recomendação: comece com JSON. Migre para SQLite só quando tiver centenas de sessões ou precisar de busca
Claude Code usa: JSON para sessões + SQLite para índice de busca — o melhor dos dois mundos
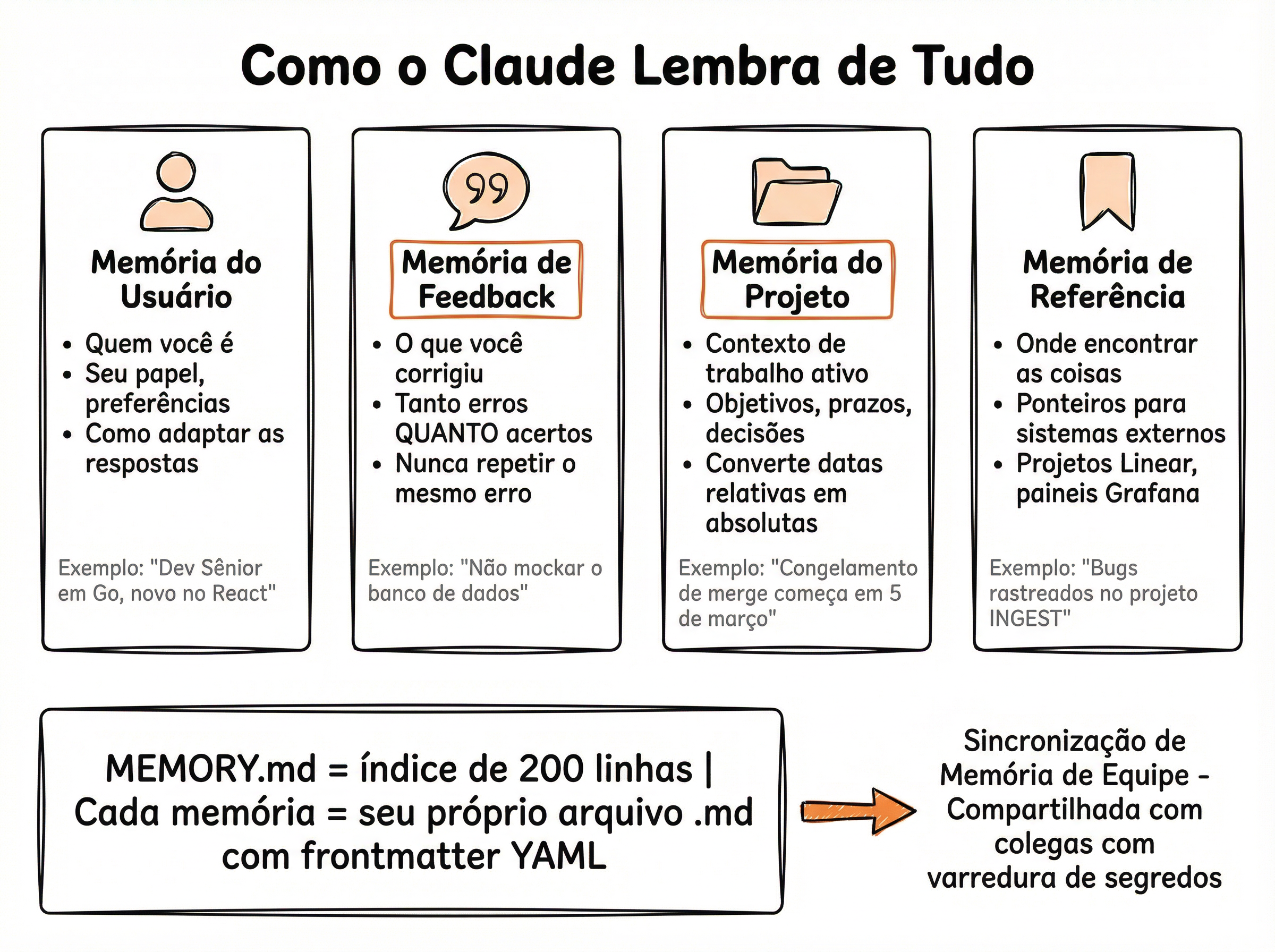
📝 4 Tipos de Memória
O Claude Code não tem apenas uma memória genérica — ele separa em 4 tipos temáticos, cada um com propósito diferente. Essa separação facilita a manutenção, evita poluição entre contextos e permite que o agente carregue apenas o que é relevante para a tarefa atual.
Implementação dos 4 Tipos
# memory/user.md — quem é o usuário
# memory/feedback.md — correções e acertos
# memory/project.md — contexto ativo
# memory/reference.md — links externos
# MEMORY.md — índice (~150 chars/linha)user.md: preferências, estilo de código, stack favorita — o "perfil" do usuário
feedback.md: quando o usuário corrige o agente, a correção é salva aqui para não repetir o erro
project.md: arquitetura do projeto atual, decisões técnicas, convenções — contexto ativo
reference.md: links para docs, APIs externas, exemplos — referências que o agente pode consultar
MEMORY.md (índice): lista resumida de todos os fatos (~150 chars/linha) — o que cabe na context window
💡 Mantenha o Índice Curto
O MEMORY.md é injetado no system prompt a cada chamada. Se ele ficar grande demais, consome contexto precioso. Limite cada linha a ~150 caracteres e o arquivo total a ~200 linhas. Use os arquivos de tópico (user.md, feedback.md etc.) para o conteúdo detalhado — o índice só aponta para eles.
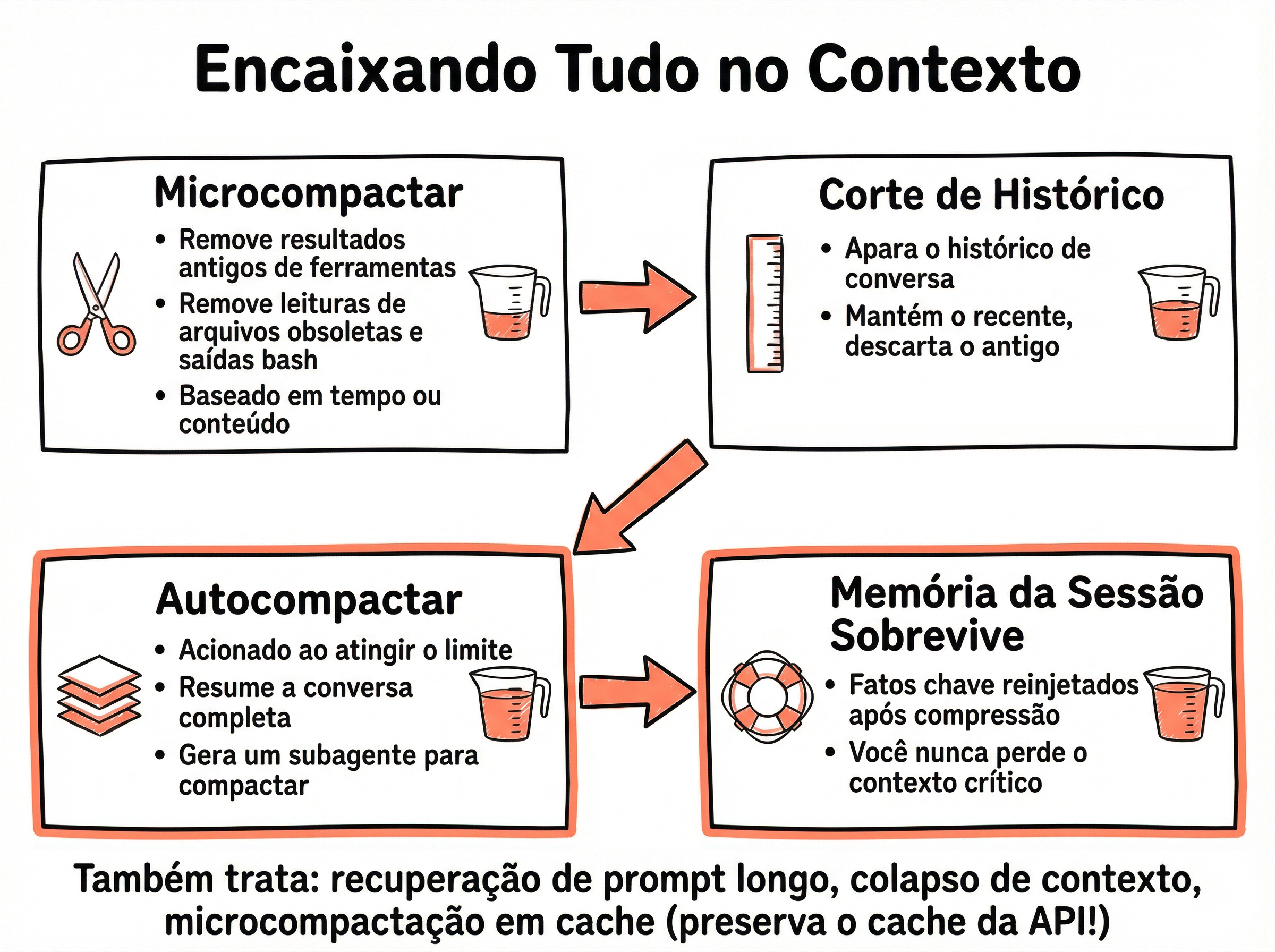
📦 Compressão: Sliding Window
Quando a lista de mensagens ultrapassa o limite de contexto, a técnica mais simples é a sliding window: manter as mensagens do sistema + as N mensagens mais recentes que cabem no orçamento de tokens. Mensagens antigas são descartadas silenciosamente. É brutal, mas funciona.
Implementação de Sliding Window
def trim_messages(messages, max_tokens=30000, chars_per_token=3.5):
system = [m for m in messages if m['role'] == 'system']
non_system = [m for m in messages if m['role'] != 'system']
budget = max_tokens * chars_per_token
kept = []
used = sum(len(str(m)) for m in system)
for msg in reversed(non_system):
if used + len(str(msg)) > budget: break
kept.insert(0, msg)
used += len(str(msg))
return system + keptSystem messages preservadas: nunca descarte o system prompt — ele define o comportamento
Iteração reversa: começa pelas mensagens mais recentes, que são mais relevantes
Estimativa de tokens: ~3.5 chars/token é uma boa aproximação para inglês; para português, use ~4.0
📊 Limitações da Sliding Window
Perda de contexto: decisões importantes tomadas no início da sessão podem ser perdidas
Sem gradação: uma mensagem está 100% dentro ou 100% fora — não há "resumo parcial"
Solução híbrida: combine sliding window com resumo (tópico 5) para manter o essencial das mensagens antigas
🤖 Compressão: Resumo com LLM
Em vez de simplesmente descartar mensagens antigas, podemos pedir para um LLM resumi-las. O resumo preserva as decisões e o contexto essencial em muito menos tokens. O Claude Code chama isso de "compactação" e usa internamente quando o contexto atinge ~80% do limite.
Resumo Automático com LLM
def summarize_history(messages, model='qwen3:4b'):
history = '\n'.join(
f"{m['role']}: {str(m['content'])[:500]}"
for m in messages if m['role'] != 'system'
)
response = chat(
model=model,
messages=[{
'role': 'user',
'content': f'Summarize concisely:\n{history}'
}],
options={'num_ctx': 8192}
)
return response.message.contentModelo pequeno: use um modelo rápido e barato para o resumo — não precisa ser o modelo principal
Truncamento preventivo: limita cada mensagem a 500 chars antes de enviar para resumo
Resultado: o resumo substitui as N mensagens antigas, liberando espaço no contexto
💡 Use Modelo Rápido/Pequeno para Resumos
Não gaste tokens do seu modelo principal (Sonnet, GPT-4) para comprimir contexto. Use um modelo local como Qwen3:4b ou Llama 3.2:3b via Ollama. O resumo não precisa ser perfeito — precisa ser rápido e capturar os pontos principais. Um modelo de 4B parâmetros faz isso em menos de 2 segundos.
🌙 Consolidação Automática
O Claude Code tem um sistema chamado AutoDream: periodicamente, ele analisa sessões recentes, extrai fatos importantes e atualiza os arquivos de memória. Podemos implementar uma versão simplificada que roda a cada 24h (ou manualmente) e consolida o conhecimento acumulado.
AutoDream Simplificado
def auto_consolidate(session_dir, memory_dir):
"""Run every 24h if 5+ new sessions exist"""
sessions = sorted(Path(session_dir).glob('*.json'))
recent = sessions[-5:]
facts = []
for s in recent:
data = json.loads(s.read_text())
# Extract key decisions, files touched, errors
facts.extend(extract_facts(data['messages']))
# Update memory topic files
update_memory_files(memory_dir, facts)
# Prune MEMORY.md index to < 200 lines
prune_index(memory_dir / 'MEMORY.md')Trigger: roda a cada 24h se houver 5+ sessões novas — evita processamento desnecessário
extract_facts: usa LLM para extrair decisões, arquivos tocados, erros e aprendizados
Pruning: mantém MEMORY.md abaixo de 200 linhas, removendo fatos obsoletos ou duplicados
Fazer
- ✓ Separar memória em tipos temáticos (user, feedback, project, reference)
- ✓ Salvar sessões incrementalmente após cada interação
- ✓ Consolidar automaticamente com trigger baseado em volume
- ✓ Manter o índice MEMORY.md curto e objetivo (<200 linhas)
Evitar
- ✗ Jogar tudo num arquivo só sem categorização
- ✗ Ignorar limites de tamanho e deixar a memória crescer infinitamente
- ✗ Usar o modelo principal para tarefas de resumo/consolidação
- ✗ Consolidar a cada sessão — processar com muita frequência gasta tokens sem ganho
📋 Resumo do Módulo
Próximo Módulo:
5.4 - 🛡️ Segurança e Permissões