📏 Janela de Contexto
A janela de contexto é o limite de tokens que o LLM processa de uma vez. Tudo — system prompt, histórico, schemas de ferramentas, resultados — precisa caber nessa janela. Quando ultrapassa, algo precisa ser cortado. Modelos variam de 8K tokens (modelos locais) a 1M tokens (Claude).
Janelas de Contexto por Modelo
| Modelo | Contexto | Nota |
|---|---|---|
| Modelos locais (Llama, etc.) | 8K - 32K | Muito limitado para agentes complexos |
| GPT-4o | 128K | Suficiente para a maioria das tarefas |
| Claude Sonnet/Haiku | 200K | Amplo para projetos médios |
| Claude Opus (1M) | 1M | Cabe codebases inteiras no contexto |
💡 Contexto Grande Não Significa Infinito
Mesmo com 1M de tokens, a qualidade degrada em contextos muito longos — o modelo tende a "esquecer" informações no meio. Além disso, mais tokens = mais custo e mais latência. A melhor estratégia é manter o contexto enxuto e relevante, independente do limite máximo disponível.
🧠 Contexto = Memória de Trabalho
O que está no contexto, o agente sabe. O que não está, não existe. É como a RAM de um computador — rápida, acessível, mas limitada. Se você remove algo do contexto, o agente esquece completamente. Não há "lembrança vaga" — é binário: está lá ou não.
Contexto é Tudo que o Agente Sabe
Presente = sabe — se a informação está no contexto, o agente pode usá-la
Ausente = não existe — sem "lembrança parcial" — é tudo ou nada
Posição importa — informações no início e no fim do contexto são mais bem lembradas
Analogia: RAM — rápida e acessível, mas volátil e limitada em tamanho
📊 O Que Consome Contexto
System prompt: instruções base, CLAUDE.md, regras — sempre presente, consome contexto fixo
Histórico de mensagens: cada mensagem trocada acumula tokens — cresce a cada turno
Tool schemas: a descrição de cada ferramenta disponível ocupa espaço no contexto
Resultados de ferramentas: o output de cada chamada de ferramenta volta para o contexto
💾 Memória Persistente vs Sessão
Memória de sessão são as mensagens da conversa atual — desaparecem quando a sessão termina. Memória persistente sobrevive entre sessões — é salva em disco e recarregada automaticamente. Um agente eficaz usa ambas estrategicamente.
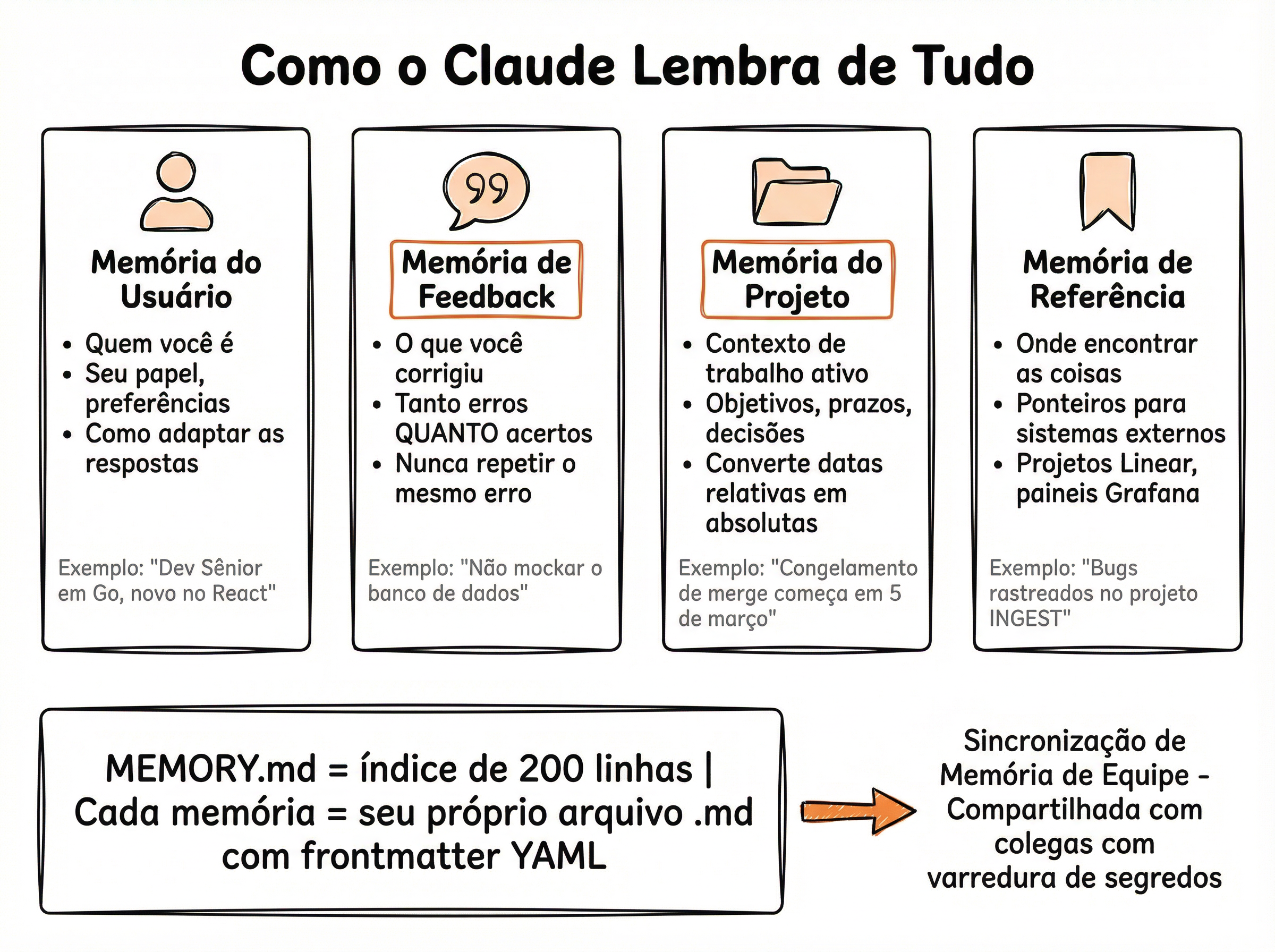
4 Tipos de Memória no Claude Code
Memória de Usuário — preferências pessoais salvas em ~/.claude/CLAUDE.md, carregadas em toda sessão
Memória de Feedback — correções do usuário que o agente salva para não repetir erros
Memória de Projeto — regras e padrões do projeto em CLAUDE.md na raiz do repositório
Memória de Referência — documentação e guias que o agente pode consultar sob demanda
📊 Sessão vs Persistente na Prática
Sessão: histórico de mensagens, resultados de ferramentas, estado da tarefa atual — tudo volátil
Persistente: CLAUDE.md, settings.json, feedback salvo — sobrevive entre sessões
Carregamento: memória persistente é injetada no início do contexto de cada nova sessão
Custo: memória persistente consome tokens fixos em toda sessão — mantenha-a enxuta
📦 Compressão de Contexto
Quando o contexto fica cheio, o Claude Code ativa um pipeline de compressão em 4 estágios. Cada estágio remove informação menos importante, mantendo o essencial. Entender esse pipeline é chave para manter a qualidade em sessões longas.
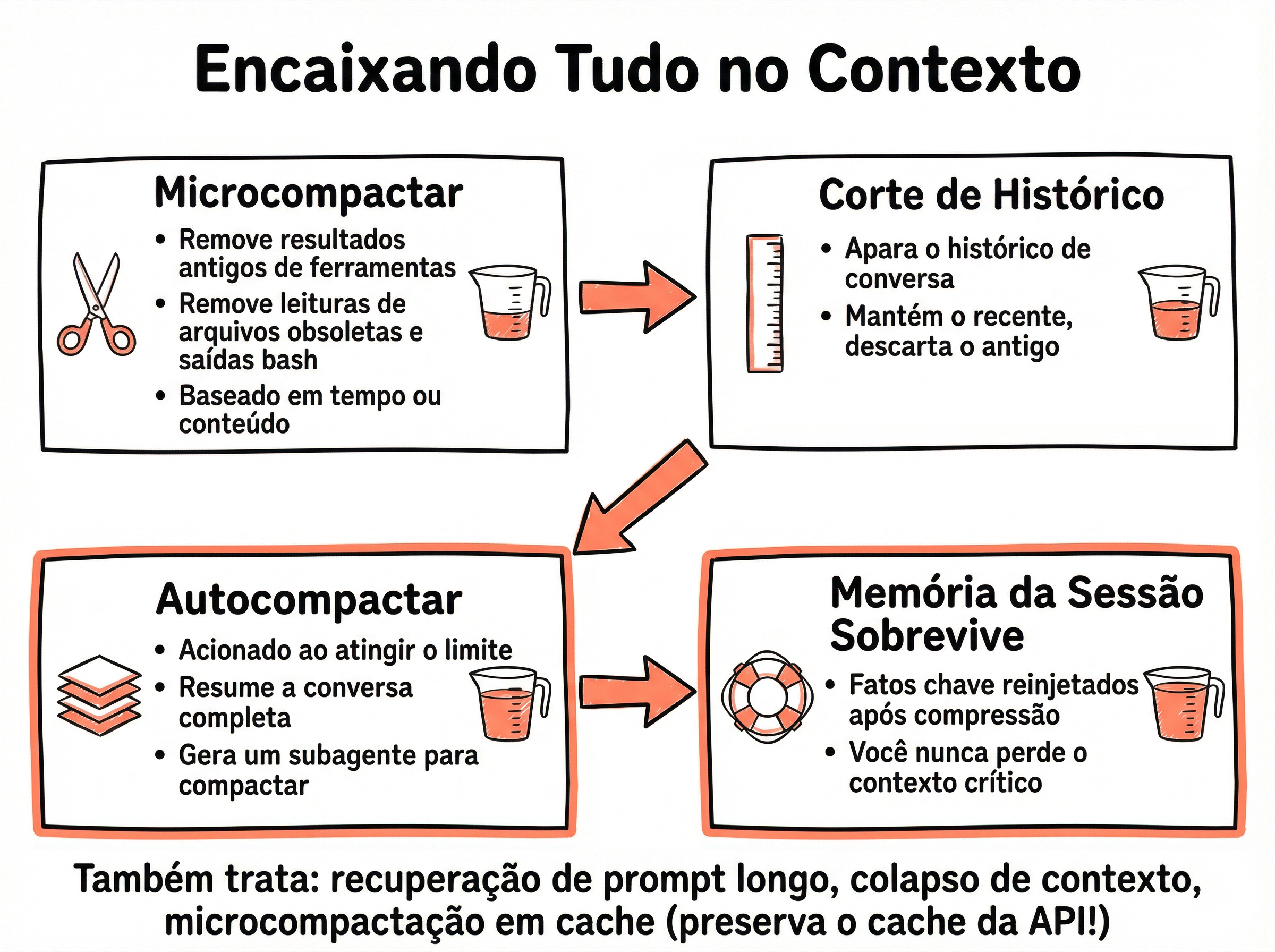
Pipeline de Compressão em 4 Estágios
1. Microcompact — comprime resultados de ferramentas grandes (ex: outputs de grep com centenas de linhas) mantendo apenas as partes relevantes
2. Corte de Histórico — remove mensagens antigas do início da conversa, preservando as mais recentes e o system prompt
3. Autocompact — o LLM resume a conversa inteira em um sumário conciso, substituindo o histórico original
4. Session Memory — salva o sumário em disco para que a próxima sessão comece com contexto residual
💡 Quando Usar /compact
Use /compact manualmente quando perceber que o agente está "esquecendo" coisas que você disse antes, quando as respostas ficam mais lentas, ou quando você muda de assunto drasticamente. O comando força o estágio 3 (Autocompact), liberando espaço sem perder o essencial. Em sessões longas, faça /compact a cada 30-40 mensagens como hábito.
📝 System Prompt como DNA
O system prompt define a personalidade, regras e capacidades do agente. É a primeira coisa no contexto e permanece lá em toda interação. Pense nele como o DNA — determina o comportamento fundamental, mas consome espaço fixo valioso.
System Prompt = Identidade do Agente
Sempre presente — o system prompt é injetado no início de toda requisição ao LLM
Define personalidade — tom, estilo, idioma, nível de detalhe das respostas
Define regras — o que o agente pode e não pode fazer, limites de segurança
Define capacidades — lista de ferramentas disponíveis e como usá-las
Fazer
- ✓ System prompt curto e objetivo — cada token conta
- ✓ Incluir regras de segurança claras e não-ambíguas
- ✓ Definir o formato esperado de respostas
- ✓ Separar instruções permanentes de contextuais
Evitar
- ✗ System prompt longo e genérico — desperdiça contexto valioso
- ✗ Repetir instruções que já estão nas descrições de ferramentas
- ✗ Incluir exemplos extensos que raramente são necessários
- ✗ Misturar regras de segurança com dicas de estilo
📋 CLAUDE.md e Configuração
O CLAUDE.md é o manual do projeto — contém regras, padrões e decisões arquiteturais que o agente precisa seguir. O settings.json controla permissões e comportamento. Juntos, eles separam configuração do código e tornam o agente previsível e controlável.
CLAUDE.md + settings.json = Controle Total
CLAUDE.md na raiz do projeto — regras, padrões, arquitetura. Carregado automaticamente no início de cada sessão
~/.claude/CLAUDE.md — preferências pessoais que se aplicam a todos os projetos
settings.json — permissões de ferramentas, configurações de segurança, variáveis de ambiente
Separação clara — CLAUDE.md para "o quê" (regras), settings.json para "como" (permissões)
💡 Na Próxima Trilha Você Implementa Tudo Isso em Python
Tudo o que vimos nesta trilha — loop agentic, ferramentas, permissões, memória, contexto — será implementado na prática na Trilha 5 (Prática). Você vai construir um agente Python completo com essas 4 ferramentas essenciais, sistema de memória persistente e gerenciamento de contexto. A teoria desta trilha é o blueprint; a próxima é a construção.
📋 Resumo do Módulo
Próxima Trilha:
Trilha 5 — Prática: Construindo seu Agente Python