📝 As Etapas do Loop
O loop do agente tem 6 etapas bem definidas — as mesmas que o Claude Code executa em cada iteração. Entender cada etapa é entender como qualquer agente funciona, porque todos seguem esse mesmo padrão fundamental.
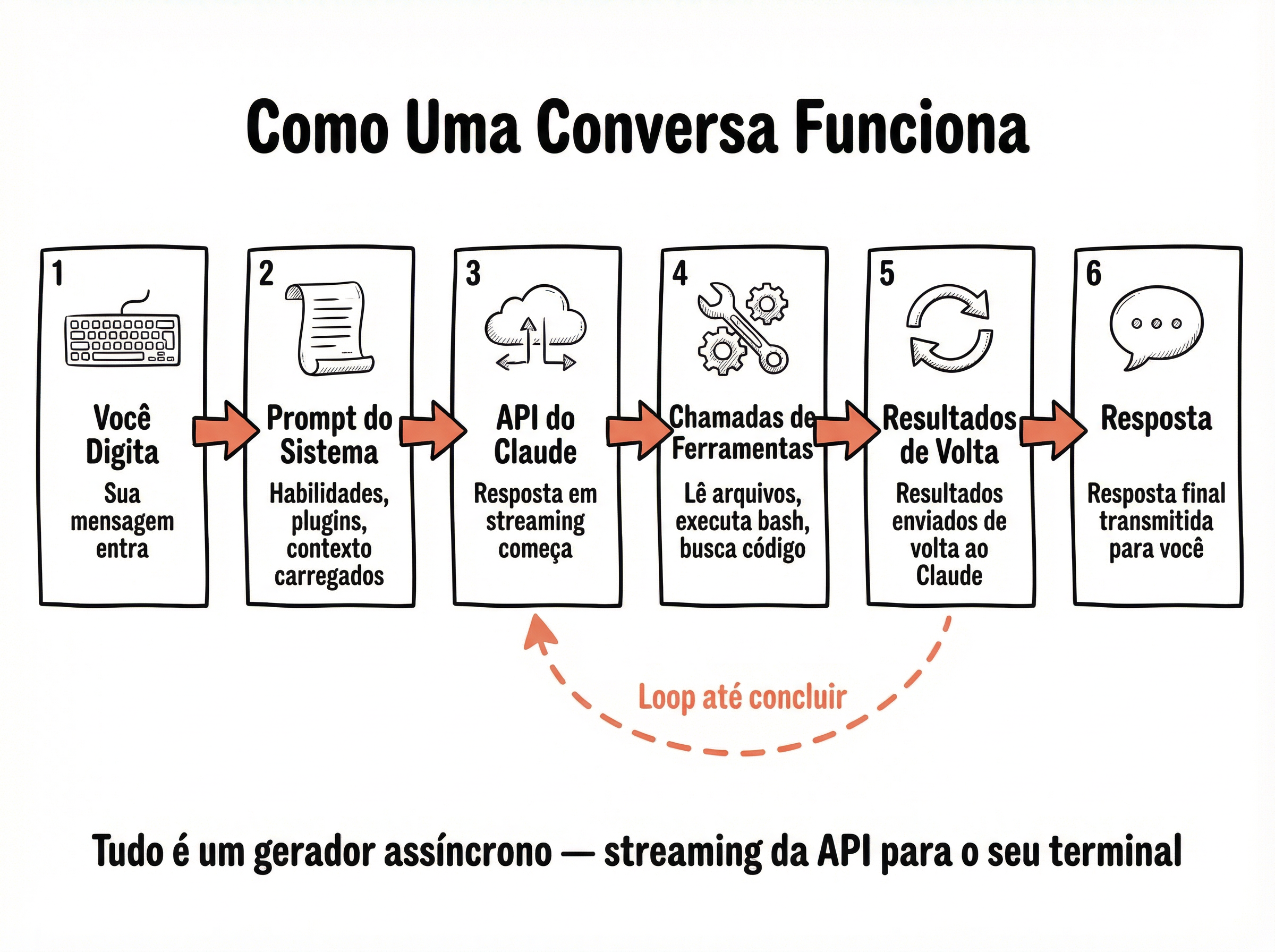
Receber Input
Mensagem do usuário ou resultado de ferramenta entra na fila de mensagens
Montar Contexto
System prompt + memória + histórico de conversa + definições de ferramentas
Chamar o LLM
Enviar tudo para a API e receber a resposta (texto + possíveis tool_calls)
Verificar Tool Calls
Se não há tool_calls, o loop termina. Se há, continua para execução
Executar Ferramentas
Rodar cada ferramenta solicitada (possivelmente em paralelo) e coletar resultados
Adicionar Resultados
Resultados das ferramentas entram como novas mensagens — volta para etapa 1
Por Que Essas 6 Etapas?
Separação de responsabilidades: cada etapa faz uma coisa só, facilitando debug e extensão
Composabilidade: você pode trocar o LLM, adicionar ferramentas ou mudar o contexto sem alterar o loop
Padrão universal: OpenAI, Anthropic, Google — todos usam o mesmo padrão de tool_calls no loop
♾️ Por Que o Loop é Infinito
O while(true) não é um bug — é uma feature. O loop precisa ser infinito porque o agente não sabe de antemão quantas iterações vai precisar. Uma tarefa pode levar 1 iteração (pergunta simples) ou 50 (refatoração complexa). O número é determinado pelo LLM em tempo de execução.
O Poder do Loop Infinito
Número variável de passos: o mesmo agente resolve tarefas de 1 passo e tarefas de 50 passos
LLM como controlador: é o modelo que decide quando parar, não o código
Adaptação dinâmica: se uma ferramenta falha, o LLM pode tentar outra abordagem no próximo ciclo
Emergência: comportamentos complexos emergem de iterações simples repetidas
💡 Loop Infinito com Segurança
Todo loop infinito precisa de um safety net. O Claude Code usa max_iterations e timeout para evitar que o agente rode para sempre. Quando implementar seu próprio loop, sempre defina um limite máximo de iterações (comece com 25-50) e um timeout global. Melhor parar cedo do que gastar tokens infinitamente.
🛑 Quando o Agente Para
O loop infinito tem três condições de parada. Entender quando e por que o agente para é tão importante quanto entender como ele roda. Um agente que não para é tão inútil quanto um agente que para cedo demais.
As 3 Condições de Parada
Sem tool_calls: o LLM respondeu sem solicitar nenhuma ferramenta — tarefa completa
Max iterations: atingiu o limite de segurança — o agente não conseguiu terminar no tempo previsto
Erro irrecuperável: API fora do ar, timeout, ou erro que o fallback não consegue resolver
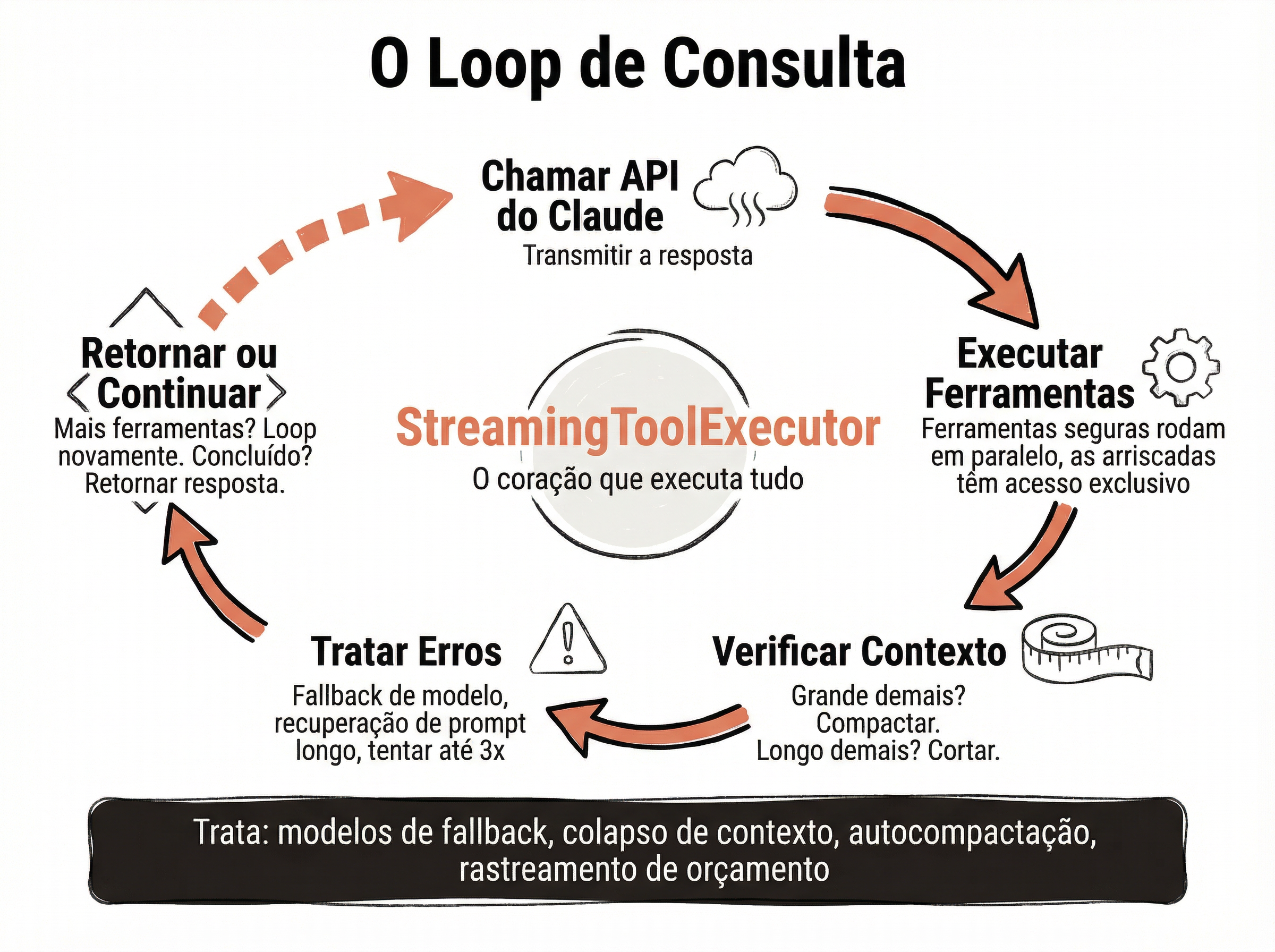
📊 Como o Claude Code Lida com Cada Parada
Parada normal: response.stop_reason === "end_turn" — o modelo decidiu que terminou
Parada por limite: contador de iterações atinge o máximo — log de warning + resposta parcial
Parada por erro: retry com backoff exponencial → fallback de modelo → abort com mensagem de erro
Context window cheia: AutoDream resume a conversa e o loop continua com contexto comprimido
🌊 Streaming vs Batch
Existem duas formas de processar a resposta do LLM dentro do loop: streaming (tokens chegam um a um em tempo real) e batch (espera a resposta inteira antes de processar). O Claude Code usa streaming com async generators, permitindo que o usuário veja progresso imediato enquanto o agente trabalha.
Streaming vs Batch no Loop
Streaming: tokens chegam progressivamente — UX melhor, o usuário vê o agente "pensando"
Batch: espera a resposta completa — mais simples de implementar, mas UX de "tela preta"
Async generators: o Claude Code usa yield para emitir eventos conforme chegam
Tool calls parciais: mesmo durante streaming, o agente detecta tool_calls incrementalmente
Fazer
- ✓ Usar streaming para qualquer interface interativa (CLI, web)
- ✓ Mostrar indicador de progresso enquanto ferramentas executam
- ✓ Processar tool_calls assim que detectados no stream
- ✓ Usar batch apenas para scripts automatizados sem interação
Evitar
- ✗ Esperar resposta completa antes de começar a processar
- ✗ Ignorar erros de stream parciais (tratar como fatais)
- ✗ Acumular todo o stream em memória antes de processar
- ✗ Misturar lógica de streaming com lógica de negócio no mesmo handler
⚠️ Tratamento de Erros
Erros são inevitáveis em agentes. Ferramentas falham, APIs caem, arquivos não existem. A genialidade do loop é que erros de ferramentas não são fatais — eles voltam para o LLM como contexto, e o modelo tenta outra abordagem. O agente se auto-corrige.
Erros Como Contexto
Erro da ferramenta: resultado com is_error: true volta como mensagem normal para o LLM
LLM adapta: ao ver o erro, o modelo muda de estratégia — tenta outro arquivo, outro comando, outra abordagem
Fallback de modelo: se o modelo principal falha (rate limit, timeout), o sistema tenta automaticamente um modelo alternativo
Retry com backoff: erros transitórios (rede, rate limit) são retentados com espera exponencial
🚨 Erros Comuns em Loops de Agente
Loop infinito de erros: ferramenta falha → LLM tenta a mesma coisa → falha de novo. Solução: detectar repetição e forçar mudança de estratégia
Context window envenenada: muitos erros acumulados enchem o contexto de lixo. Solução: limpar mensagens de erro antigas após N iterações
Silenciar erros: ignorar erros de ferramentas faz o LLM "inventar" resultados. Solução: sempre retornar o erro real como contexto
Sem fallback: depender de um único modelo é ponto de falha. Solução: ter pelo menos um modelo alternativo configurado
📋 Seu Primeiro Loop em Pseudocódigo
Agora que você entende as etapas, as condições de parada, streaming e erros — aqui está o pseudocódigo completo de um loop de agente. Este é o esqueleto que todo agente segue, do Claude Code ao AutoGPT.
Pseudocódigo do Loop do Agente
// 1. Inicializar
messages = [system_prompt]
tools = load_tools()
max_iterations = 50
// 2. Loop principal
while True:
// 3. Chamar o LLM
response = llm.create(
messages = messages,
tools = tools
)
// 4. Adicionar resposta ao histórico
messages.append(response.message)
// 5. Verificar se há tool_calls
if not response.tool_calls:
return response.text // Pronto!
// 6. Executar cada ferramenta
for tool_call in response.tool_calls:
result = execute_tool(
name = tool_call.name,
args = tool_call.arguments
)
// 7. Resultado volta como mensagem
messages.append({
role: "tool",
tool_call_id: tool_call.id,
content: result
})
// 8. Safety net
max_iterations -= 1
if max_iterations <= 0:
return "Limite de iterações atingido"~20 linhas: o loop inteiro cabe em 20 linhas de pseudocódigo. A simplicidade é proposital
Sem mágica: é um while loop com if/for. O poder vem da combinação LLM + tools, não do código
Extensível: adicione streaming, parallelismo, retry — o esqueleto permanece o mesmo
💡 Na Próxima Trilha: Implementação Real
Este pseudocódigo é o mapa. Na Trilha 5 (Prática), você vai implementar esse loop de verdade — com Python + Anthropic SDK, ferramentas reais, streaming e tratamento de erros. Por agora, o objetivo é entender a lógica. Quando for implementar, vai perceber que o código real é surpreendentemente parecido com o pseudocódigo.
📋 Resumo do Módulo
Próximo Módulo:
4.3 - Ferramentas e Tool Use