📏 O Problema — Janela finita vs sessões longas
Todo modelo de linguagem opera dentro de uma janela de contexto finita. O Claude Sonnet, por exemplo, aceita até 200K tokens de entrada. Parece muito — até você perceber que uma sessão de desenvolvimento real gera conteúdo a uma velocidade assustadora: cada arquivo lido, cada comando executado, cada resposta gerada consome tokens. Em sessões longas, o contexto simplesmente estoura.
O Problema da Entropia Contextual
Janela finita: O modelo tem um limite rígido de tokens que pode processar por vez (ex: 200K tokens de entrada)
Crescimento exponencial: Cada tool_use (leitura de arquivo, busca, comando) adiciona centenas ou milhares de tokens ao histórico
Entropia contextual: Quanto mais informação irrelevante acumulada, mais o modelo se confunde — a qualidade das respostas degrada
Custo financeiro: Cada token processado custa dinheiro — contexto inflado = conta mais alta sem benefício
⚠️ O Que Acontece Sem Gerenciamento de Contexto
Alucinação por diluição: Informações antigas e irrelevantes competem com as recentes — o modelo começa a "inventar" porque não consegue distinguir o que importa
Erro de contexto: A sessão simplesmente falha quando atinge o limite — sem aviso, sem recuperação
Custo desnecessário: Processar 200K tokens repetidamente quando 50K seriam suficientes multiplica a conta por 4x
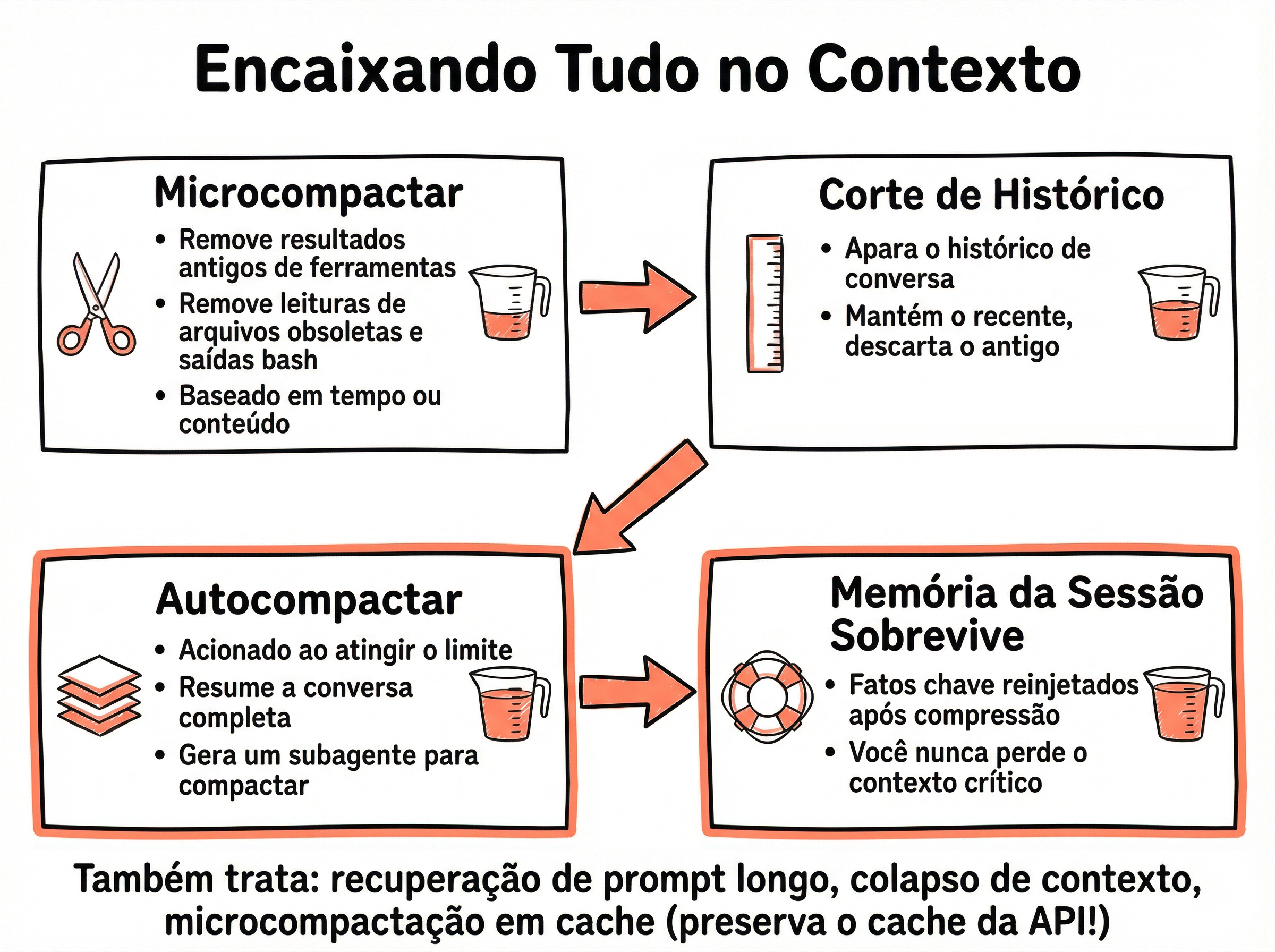
🗑️ Estágio 1: Microcompactar — Limpar saídas antigas de ferramentas
O primeiro estágio é o mais gentil e também o mais frequente. A ideia é simples: quando uma ferramenta foi usada há várias rodadas, o resultado detalhado dela não é mais relevante. O fato de que a ferramenta foi chamada permanece no histórico ("leu o arquivo X"), mas a saída completa (o conteúdo inteiro do arquivo) é removida. Isso preserva a narrativa da conversa enquanto libera grandes blocos de tokens.
Como Funciona a Microcompactação
Alvo: Blocos tool_result de rodadas antigas — outputs de Read, Bash, Grep, etc.
O que fica: O registro de que a ferramenta foi chamada e seus parâmetros (ex: "leu /src/main.ts")
O que vai: O conteúdo completo retornado pela ferramenta (ex: as 500 linhas do arquivo)
Quando: Automaticamente, para outputs de ferramentas que estão além de um threshold de distância da rodada atual
Impacto zero na narrativa: O modelo ainda sabe que leu o arquivo — só não tem mais o conteúdo bruto na memória de trabalho
💡 Economia Real de Tokens
Um único Read de arquivo grande pode consumir 5.000–20.000 tokens. Se a sessão leu 10 arquivos nas primeiras rodadas, são potencialmente 100K+ tokens que não precisam mais estar no contexto. A microcompactação sozinha pode reduzir o contexto em 40–60% sem perda de qualidade.
✂️ Estágio 2: Corte de Histórico — Aparar rodadas antigas
Quando a microcompactação não é suficiente, o sistema passa para o segundo estágio: cortar rodadas inteiras de conversa. As interações mais recentes ficam intactas (são as mais relevantes para o contexto atual), enquanto as mais antigas são completamente removidas. É uma poda temporal — o que aconteceu há 30 rodadas provavelmente não é mais relevante para o que está acontecendo agora.
Como Funciona o Corte de Histórico
Princípio: Rodadas recentes são mais valiosas que antigas — recência como proxy de relevância
Mecanismo: Remove pares completos de mensagem (user + assistant) das primeiras rodadas da conversa
Preservação: System prompt e mensagens recentes nunca são cortados
Progressivo: Corta apenas o mínimo necessário para voltar abaixo do threshold
📊 Como Decide o Que Cortar
Ordem cronológica: Sempre começa pelas rodadas mais antigas — as mais distantes do momento presente
Threshold configurável: O sistema monitora a porcentagem de uso da janela e aciona o corte quando ultrapassa o limite definido
Granularidade: Rodadas inteiras são a unidade — não corta no meio de uma interação
Idempotente: Pode ser aplicado múltiplas vezes sem efeitos colaterais — cada aplicação corta mais rodadas antigas
🔄 Estágio 3: Autocompactar — Resumo inteligente do histórico
O estágio mais sofisticado. Quando o contexto atinge um limite crítico e os estágios anteriores não foram suficientes, o Claude Code aciona um subagente dedicado. Esse subagente recebe o histórico completo da conversa e produz um resumo compactado — preservando decisões, fatos-chave e estado atual do trabalho, descartando detalhes intermediários. O resultado substitui todo o histórico anterior.
Como Funciona a Autocompactação
Trigger automático: Ativado quando o uso de contexto ultrapassa o threshold (tipicamente ~80% da janela)
Subagente dedicado: Uma instância separada do Claude lê todo o histórico e gera um resumo estruturado
O que preserva: Decisões tomadas, arquivos modificados, erros encontrados, estado atual da tarefa, preferências do usuário
O que descarta: Tentativas intermediárias, saídas de debug, explorações que não levaram a nada
Substituição total: O resumo compactado substitui completamente o histórico anterior — a conversa "recomeça" com contexto condensado
💡 Quando Usar /compact Manualmente
Você não precisa esperar o sistema acionar a autocompactação automaticamente. O comando /compact permite forçar uma compactação a qualquer momento — e é estratégico fazer isso:
Ao mudar de tarefa: Terminou uma feature e vai começar outra? /compact limpa o ruído da tarefa anterior
Após debug extenso: Sessões de debug geram muita saída — compactar preserva apenas a solução
Antes de tarefas complexas: Garanta contexto limpo antes de pedir algo que vai gerar muito output
💾 Estágio 4: Memória da Sessão — Fatos-chave que sobrevivem à compressão
A compressão, por mais inteligente que seja, sempre perde alguma informação. Para mitigar isso, o Claude Code mantém um sistema de memória da sessão: fatos-chave são marcados e reinjetados automaticamente após qualquer compressão. Isso garante que o contexto crítico — como decisões arquiteturais, preferências do usuário e estado do projeto — nunca se perca, independentemente de quantas vezes o histórico foi compactado.
Memória da Sessão: Persistência Seletiva
CLAUDE.md: O arquivo de memória principal — sempre reinjetado no início de cada conversa e após cada compactação
Fatos extraídos: Durante a autocompactação, o subagente identifica fatos-chave e os marca para persistência
Hierarquia de memória: Memória global (~/.claude/CLAUDE.md) + memória de projeto (./CLAUDE.md) + memória da sessão atual
Reinjeção automática: Após compactação, fatos-chave são adicionados ao início do contexto compactado
📊 O Que Sobrevive à Compressão
Sempre sobrevive: System prompt, CLAUDE.md, preferências de usuário, configurações de permissão
Sobrevive por importância: Decisões arquiteturais, bugs encontrados, padrões do projeto, convenções de código
Descartado: Conteúdo bruto de arquivos, saídas de comandos, explorações sem resultado, mensagens de debug
Resultado: Após compactação, o contexto é menor mas mais denso em informação útil — melhor relação sinal/ruído
💰 Microcompactação em Cache — Comprimir sem desperdiçar cache
Uma variante especial e elegante do primeiro estágio. A API do Claude suporta prompt caching — um prefixo estável do prompt é armazenado em cache e reutilizado entre chamadas, reduzindo custo e latência. O problema: se você remove ou modifica qualquer parte do prefixo cacheado, o cache inteiro é invalidado. A microcompactação em cache resolve isso usando a API de cache editing para remover outputs de ferramentas sem quebrar o prefixo em cache.
Cache-Aware Microcompaction
Prompt caching: A API armazena um prefixo estável do prompt — chamadas subsequentes reutilizam esse cache, pagando ~90% menos por esses tokens
O dilema: Microcompactação normal modifica o histórico → quebra o cache → próxima chamada paga preço cheio por todos os tokens
A solução: Cache editing API permite remover blocos específicos de tool_result sem invalidar o prefixo cacheado
Resultado: Compressão de contexto + preservação de cache = economia dupla (menos tokens E tokens mais baratos)
💡 Impacto no Custo
O prompt caching da API do Claude oferece desconto de ~90% em tokens cacheados. Se o prefixo tem 100K tokens e você quebra o cache, a próxima chamada paga preço cheio por todos eles. A microcompactação cache-aware evita essa armadilha — você continua comprimindo o contexto, mas o cache permanece válido. Em sessões longas com muitas chamadas, isso pode representar uma economia de 50–70% no custo total da sessão.
Fazer
- ✓ Usar /compact proativamente ao mudar de tarefa
- ✓ Manter CLAUDE.md atualizado com fatos-chave do projeto
- ✓ Confiar no pipeline automático para sessões normais
- ✓ Iniciar novas sessões para tarefas completamente diferentes
Evitar
- ✗ Sessões infinitas sem compactação — o contexto vai degradar
- ✗ Colar arquivos inteiros no prompt quando Read funciona
- ✗ Ignorar sinais de degradação de qualidade nas respostas
- ✗ Repetir informações que já estão no CLAUDE.md
📋 Resumo do Módulo
Próximo Módulo:
2.4 - 🧠 Nunca Esquece: O Sistema de Memória Persistente